
개요
난해한 프로그래밍 언어 중 가장 유명한 Brainfuck.
존재 자체는 한참 전부터 알고 있었지만 별 관심은 없었는데 이번에 제대로 살펴봤다
본 글은 나무위키를 참고하여 작성했다.
문법
단 8개의 문자로 모든 과정이 처리된다.
-
> : 포인터 증가
-
< : 포인터 감소
-
+ : 포인터가 가리키는 바이트의 값을 증가
-
- : 포인터가 가리키는 바이트의 값을 감소
-
. : 포인터가 가리키는 바이트 값을 아스키 코드 문자로 출력
-
, : 포인터가 가리키는 바이트에 아스키 코드 값을 입력받음
-
[ : 포인터가 가리키는 바이트의 값이 0이 되면 짝이 되는 ]로 이동.
-
] : 포인터가 가리키는 바이트의 값이 0이 아니면 짝이 되는 [로 이동.
즉 [와 ]는 0이 아닌 동안(0이 될 때까지) 반복하는 while문이라고 할 수 있다.
기타 사항
중요한 것은 아니지만, 각 메모리 셀은 1바이트 부호없는 정수, 즉 char 자료형으로 구성되어 있으며 배열 길이는 32768이다…라고 하지만 인터프리터별로 차이가 있는 걸로 봐서 의무적인 사항은 아닌 듯하다. 여담으로 배열이 char형임을 이용하여 흥미로운 트릭을 구사할 수 있다.
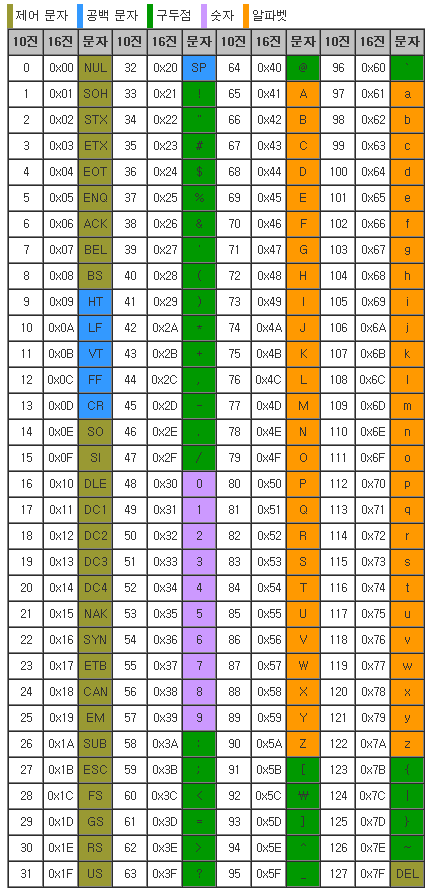
아스키 코드표
Brainfuck 코드를 작성하다 보면 언제나 아스키 코드표를 찾아 헤매게 된다. 미리 올려놓자.
입력받은 알파벳 출력하기
,.
뭐 설명할 것도 없다.
100 만들기
+를 100번 입력해도 괜찮지만, 더 좋은 방법이 있다. 이쯤에서 반복문을 소개한다.
++++++++++[>++++++++++<-]>
과정을 풀어서 보면:
-
1번 셀에 10을 대입
-
포인터 이동 -> 10 더하기 -> 포인터 복귀 -> 1 빼기 를 반복
-
포인터 한 칸 이동
괄호 규칙에 의해 2번 과정은 1번 셀이 0이 될 때까지 반복되므로 총 10회 반복,
결과적으로 2번 셀의 값은 100이 되며 3번 과정에서 포인터를 2번 셀로 이동시키는 것을 알 수 있다.
Hello World!
++++++++++
[>+++++++>++++++++++>+++<<<-]
>++.>+.+++++++..+++.>++.<<+++++++++++++++.>.+++.------.--------.>+.
일반적으로 문자열을 출력하는 과정이다. 반복문을 통해 몇 개의 셀을 적절히 초기화하고, 포인터를 옮겨 다니면서 아스키 코드를 하나씩 만들어 출력하는 것이다. 특히 이 Hello World!는 비교적 많은 사람들에 의해 코드가 작성되었는데 대부분 이 과정을 채택하고 있다.
코드마다 처음에 초기화하는 셀의 수가 다양한데, 이를 구분하기 위해 N-block 방식이라고 명명한다. 딱히 부르는 말이 없어서 필자가 만들었다. 즉 위의 코드는 [70, 100, 30]으로 구성된 3-block 방식이다.
참고로 저 문자열의 아스키 코드는
| H | e | l | l | o | W | o | r | l | d | ! | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 72 | 101 | 108 | 108 | 111 | 32 | 87 | 111 | 114 | 108 | 100 | 33 |
이다.
백준 2557: Hello World 도전기
위의 코드는 106바이트다. 효율적인 방법을 탐구하며 숏코딩에 도전해 보자.
++++++++++
[>+++++++>++++++++++>+++>+++++++++<<<<-]
>++.>+.+++++++..+++.>++.>---.<<.+++.------.--------.>+.
[70, 100, 30, 90]의 4-block 방식으로 105바이트를 만들었다. 이전 코드에서 W, 즉 87을 만들기 위해 15개의 +를 입력하는 부분을 개선하는 과정에서 90으로 초기화된 셀을 추가한 게 아이디어다.
여러 가지 요소를 비교해 보았을 때 이 4-block 방식이 최선이라고 생각했으나 같이 고민하던 친구가 놀라운 해법을 제시했다.
++++++++++++++++++
[>++++>++++++>++++++>++>+++++<<<<<-]
>.>-------.>..+++.>----.>---.<<.+++.------.<-.>>+.
반복횟수를 10회에서 18회로 늘린 5-block 방식으로 104바이트를 만들었다.
핵심 아이디어는 72와 108, 87에서 발견된다.
72=18*4
108=18*6
87=18*5-3
이므로 초깃값을 18의 배수로 만드는 게 유리하다고 판단, 한편 매우 효율적인 포인터 이동경로 최적화를 통해 위와 같은 성과를 낼 수 있었던 것이다. 실로 놀라운 코드가 아닐 수 없다.
필자는 이를 보자마자 18=6*3을 이용해 코드를 더욱 압축하여
++++++[>+++<-]>
[>++++>++++++>++++++>++>+++++<<<<<-]
>.>-------.>..+++.>----.>---.<<.+++.------.<-.>>+.
로 101바이트를 만들었다. 이때까지 백준 숏코딩 1위가 101바이트였으므로 이 코드를 제출하여 2위를 차지할 수 있었다.
1바이트를 더 줄일 요량으로 한 시간동안 저 코드를 쳐다봤으나 생각보다 어려웠다. 떠올린 해답은 출력 코드에 있는 일곱 개의 -를 줄이는 방법이었다.
++++++
[>+++[>++++>++++++>++++++>++>+++++<<<<<-]>>-<<<-]
>>.>-.>..+++.>----.>---.<<.+++.------.<-.>>+.
6*3=18을 만들어 반복하는 대신 6회 반복 내부에 3회 반복문을 넣었다.
여기까지는 바이트 수가 변하지 않는다.
그러나 안쪽 반복문이 끝난 직후 >>-<<를 추가해 2셀 오른쪽에 있는 값을 총 6만큼 감소시키면, 일곱 번의 - 대신 단 한 번만이 필요해지게 되어 결과적으로 1바이트를 아낀다.
이렇게 100바이트를 완성하여 brainfuck 숏코딩 1위를 차지할 수 있었다.
언더플로 트릭
이 또한 같이 연구하던 친구의 아이디어다.
간단히 말해 0으로 초기화된 셀에서 -가 실행되면 언더플로우가 발생해 255가 되는 점을 이용한 것이다.
-[>+>+>+>>+<<<<<---]
++++[>--->++++>++++++>++++++++<<<<-]
>-.>.>-..+++.>.>++.<<.+++.------.<-.>>+.
첫 번째 줄은 255를 3으로 나눈 85를 네 개의 셀에 초기화하는 과정이다. 이 85를 만들기 위해 언더플로 트릭이 사용되었다. 사실 이는 4-block이 아니라 5-block 방식인데, 초기화 결과가
| 85 | 85 | 85 | 0 | 85 |
이기 때문이다. 그리고 두 번째 줄에서 반복문 대입을 한 번 더 거쳐서
| 73 | 101 | 109 | 32 | 85 |
를 만든다. 두 번의 초기화 과정은 코드를 길게 만들지만, 대신 고도로 최적화된 결과를 만들어낸다. 이렇게 96바이트라는 경이로운 결과를 얻을 수 있지만…
정작 백준에서 제공하는 인터프리터는 각 셀이 char형이 아니어서 이를 사용할 수 없었다.
아무튼…이렇게 brainfuck의 첫 번째 여행이 시작되었다.
그럼 다음에,
Gabriel-Dropout
at 13:31
