
개요
Python으로 할 수 있는 일은 무궁무진하지만, 특히 편리한 작업이 몇 가지 있다.
예를 들면 알고리즘 프로토타이핑이나 머신러닝, 웹 크롤링 등등.
필자는 유튜브 동영상을 다운로드할 수 있는 프로그램을 몇 차례 만들면서 이런저런 모듈을 사용해 봤는데, 가장 유명한 모듈은 Youtube-dl과 Pytube가 아닐까 한다.
누워서 홀로라이브 영상을 보다가 갑자기 Pytube의 내부 구조가 궁금해진 관계로 일단 분석해 보자. 사실 Youtube-dl을 살펴보려고 했는데, 얘는 너무 규모가 커서 코드 읽는 데만 며칠이 걸릴지 모르기 때문에…
과정
git clone
먼저 git 레포지토리를 클론했다.
git clone https://github.com/pytube/pytube
__main__.py부터 살펴보자
__main__.py에 Youtube 클래스가 정의되어 있다. youtube video 주소를 받아서 자동으로 이것저것 추출해주는 편리한 클래스다.
Pytube는 streams에 동영상 정보를 저장하므로, 당장 필요한 건 이에 관한 정보다. line 290 에서 @property 데코레이터로 이를 정의한다.
@property
def streams(self) -> StreamQuery:
"""Interface to query both adaptive (DASH) and progressive streams.
:rtype: :class:`StreamQuery <StreamQuery>`.
"""
self.check_availability()
return StreamQuery(self.fmt_streams)
StreamQuery는 다운로드 가능한 동영상 리스트를 필터링하는 기능을 제공하는 클래스인 듯하다. 따라서 실질적인 정보는 self.fmt_streams에 있다고 추측했다.
line 159 에서 fmt_streams 선언부를 찾을 수 있다. 중간에 위치한 다음 코드를 보자.
for stream in stream_manifest:
video = Stream(
stream=stream,
monostate=self.stream_monostate,
)
self._fmt_streams.append(video)
stream_manifest의 엘리먼트를 하나씩 Stream()에 넣고 있다. stream_manifest에 영상 관련 정보가 담겨있는 것이다. 딕셔너리 타입이므로 json파일로 저장한 뒤 json viewer로 열어 보자.
import json
with open("info.json", 'w') as f:
json.dump(stream_manifest, f)
그랬더니 아래처럼 나왔다.
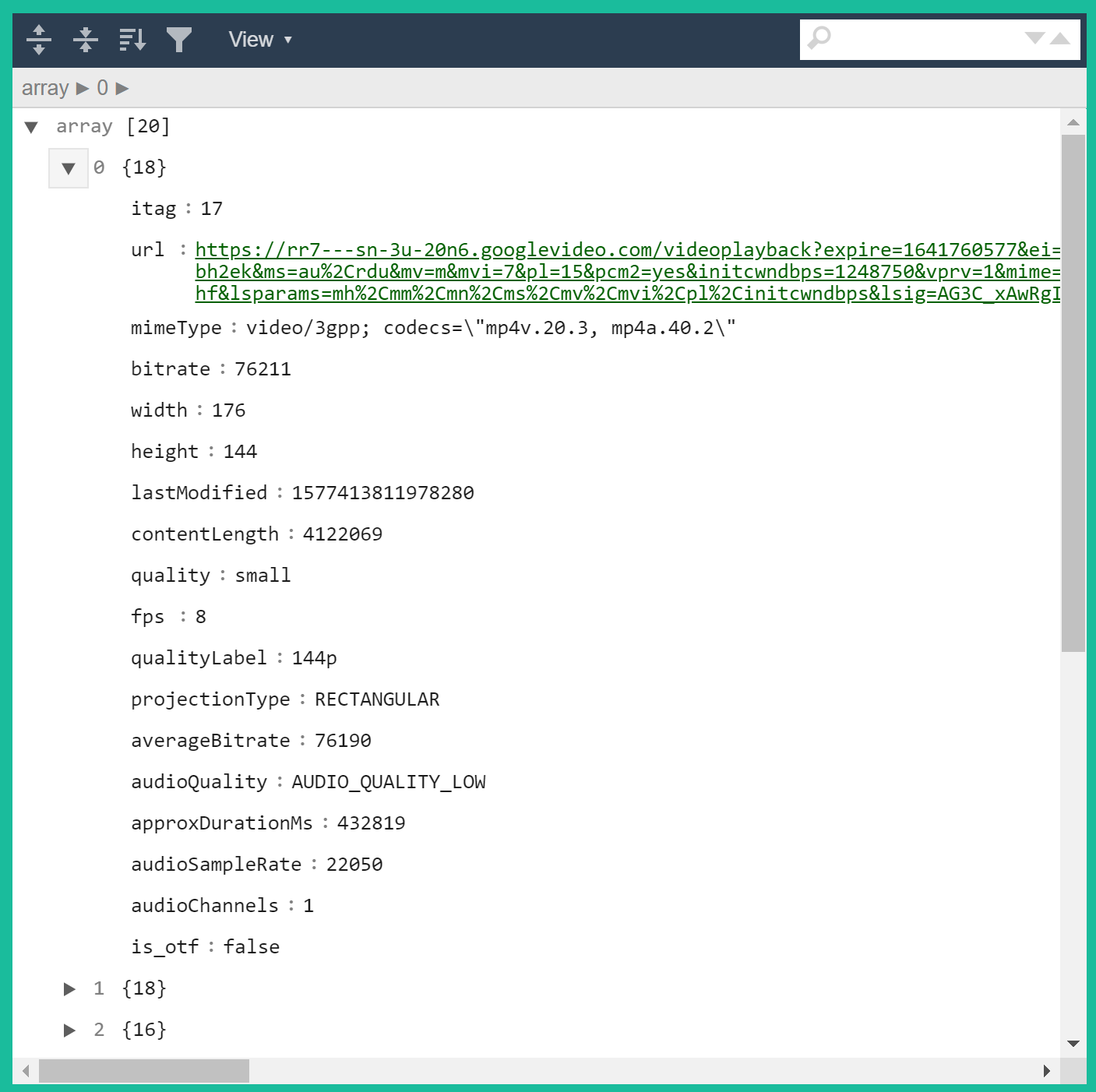
빙고! url 부분이 실제 영상 링크, 즉 다운로드 가능한 형태의 바이너리 데이터를 제공하는 주소에 해당한다. 이 링크를 어떻게 파싱했는지 분석함으로써 youtube 구조를 더 자세히 이해할 수 있지 않을까?
이에 앞서 다음 코드를 보면,
stream_manifest = extract.apply_descrambler(self.streaming_data)
extract.apply_descrambler를 확인할 필요가 있어 보인다.
line 457 에서 확인할 수 있는데, 결론부터 말하면 그냥 self.streaming_data를 정리해주는 함수다. Adaptive Format과 일반 Format 섹션을 하나로 합쳐 하나의 리스트로 만드는 과정이다. 한편 다른 작업을 함께 거치는 것으로 보이는데,
for data in formats:
if 'url' not in data:
if 'signatureCipher' in data:
cipher_url = parse_qs(data['signatureCipher'])
data['url'] = cipher_url['url'][0]
data['s'] = cipher_url['s'][0]
data['is_otf'] = data.get('type') == 'FORMAT_STREAM_TYPE_OTF'
url이라는 키값이 존재하지 않으면 signatureCipher로부터 url를 알아내는 과정으로 추측된다. 이게 무엇인지는 아래 게시글을 통해 알 수 있었다.
https://velog.io/@tan90/youtube-dl
우선 이건 나중에 보기로 하고, 원본인 self.streaming_data를 더 파보자.
line 150 에 이런 코드가 있다.
@property
def streaming_data(self):
"""Return streamingData from video info."""
if 'streamingData' in self.vid_info:
return self.vid_info['streamingData']
else:
self.bypass_age_gate()
return self.vid_info['streamingData']
self.vid_info에서 스트리밍 정보를 가져와 리턴한다. self.bypass_age_gate()는 스트리밍 정보를 불러오지 못했을 때 연령 제한 때문으로 간주하고 이를 우회하는 함수로 추정된다. self.vid_info의 선언부를 찾을 차례다.
line 235 에 이런 코드가 있다.
@property
def vid_info(self):
"""Parse the raw vid info and return the parsed result.
:rtype: Dict[Any, Any]
"""
if self._vid_info:
return self._vid_info
innertube = InnerTube(use_oauth=self.use_oauth, allow_cache=self.allow_oauth_cache)
innertube_response = innertube.player(self.video_id)
self._vid_info = innertube_response
return self._vid_info
InnerTube는 또 뭘까. 구글신께 기도를 드리니 그 답을 알 수 있었다.
InnerTube란?
https://github.com/tombulled/innertube
간단히 말해 구글이 제공하는 __Private api__를 다루는 클래스인 것 같다. 일반적으로 아는 Youtube API랑은 다르다. 아래 표에 그 차이점이 나타나 있다.
| This Library | YouTube Data API | |
|---|---|---|
| No Google account required | ✓ | ✗ |
| No request limit | ✓ | ✗ |
| Clean, reliable, well-structured data | ✗ | ✓ |
이걸 보고 깜짝 놀랐다. 저 Request Limit때문에 프로젝트 하나를 포기한 적이 있기 때문이다. Google account도 요구하지 않는 api가 있다는 사실을 알았다면 진작 저걸 사용했을 텐데. 기존 api에 비해 가공 난이도는 높아 보인다.
다시 코드를 보자.
innertube = InnerTube(use_oauth=self.use_oauth, allow_cache=self.allow_oauth_cache)
innertube_response = innertube.player(self.video_id)
use_oauth옵션은 계정 인증 설정으로 추정되는데, 기본적으로 False 이고 위의 Github 문서에서도 미구현이라고 적혀 있다.
allow_oauth_cache는 True 인데 별로 중요하진 않아 보인다.
innertube.player()는 video id 를 받아서 다양한 정보를 제공하고 있다. 역시 파보자.
innertube.py의 line 286 에서 해당 함수를 정의한다.
def player(self, video_id):
"""Make a request to the player endpoint.
:param str video_id:
The video id to get player info for.
:rtype: dict
:returns:
Raw player info results.
"""
endpoint = f'{self.base_url}/player'
query = {
'videoId': video_id,
}
query.update(self.base_params)
return self._call_api(endpoint, query, self.base_data)
_call_api의 각 인자를 순서대로 출력하면 이렇게 나온다.
https://www.youtube.com/youtubei/v1/player
{'videoId': 'V1DEVT--TCE', 'key': 'AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8', 'contentCheckOk': True, 'racyCheckOk': True}
{'context': {'client': {'clientName': 'ANDROID', 'clientVersion': '16.20'}}}
endpoint는 말 그대로 요청 uri
query는 쿼리스트링 (POST인 줄 알았는데 나중에 보니 그냥 주소에 때려박는다)
base_data는 사용자의 기본 정보를 담고 있었다. 직관적인 네이밍 아주 칭찬한다.
line 223 의 _call_api에는 최종적으로 api를 요청하는 코드가 있다.
def _call_api(self, endpoint, query, data):
"""Make a request to a given endpoint with the provided query parameters and data."""
# Remove the API key if oauth is being used.
if self.use_oauth:
del query['key']
endpoint_url = f'{endpoint}?{parse.urlencode(query)}'
headers = {
'Content-Type': 'application/json',
}
# Add the bearer token if applicable
if self.use_oauth:
if self.access_token:
self.refresh_bearer_token()
headers['Authorization'] = f'Bearer {self.access_token}'
else:
self.fetch_bearer_token()
headers['Authorization'] = f'Bearer {self.access_token}'
response = request._execute_request(
endpoint_url,
'POST',
headers=headers,
data=data
)
return json.loads(response.read())
_execute_request()는 뭔가 했는데, 그냥 리퀘스트를 보내고 리스폰스 받아오는 함수다. 다만 기본 헤더를 자동으로 설정해주고 잘못된 URL 주소 판별, 타임아웃 처리 등이 포함되어 있다.
여기까진 필요 없을 것 같고, POST 타입의 리퀘스트를 보낸다고 생각하자.
수많은 시행착오를 통해 다음과 같은 함수를 완성했다. 중간 과정을 기록하는 걸 깜빡했다.
def getInfo(video_id, client='android_embed'):
headers = {'Content-Type': 'application/json', "User-Agent": "Mozilla/5.0", "accept-language": "ko_KR,en-US;q=0.8,en;q=0.6"}
data = {
'android':{'context': {'client': {'clientName': 'ANDROID', 'clientVersion': '16.20'}}},
'android_embed':{'context': {'client': {'clientName': 'ANDROID', 'clientVersion': '16.20','clientScreen': 'EMBED'}}},
'web':{'context': {'client': {'clientName': 'WEB','clientVersion': '2.20200720.00.02'}}},
'web_embed':{'context': {'client': {'clientName': 'WEB','clientVersion': '2.20200720.00.02','clientScreen': 'EMBED'}}}
}
endpoint_url = f'https://www.youtube.com/youtubei/v1/player?videoId={video_id}&key=AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8'
response = requests.post(endpoint_url, headers=headers, json=data[client])
response_json = json.loads(response.text)
return response_json
data가 좀 특이해 보이는데, api를 요청하는 클라이언트를 4가지 중에서 선택할 수 있다. innertube.py에서 그대로 가져왔다.
이 리턴값을 잘 가공하면 여러가지 데이터를 추출할 수 있을 것이다.
참고로 contentCheckOk와 racyCheckOk는 쿼리에서 제거해도 잘 작동한다. 구글도 잘 모르는 눈치다. 다른 소스코드에선 False로 되어 있었으니 별로 중요한 건 아닌 것 같다.
Cipher 떡밥은?
Pytube는 가져온 동영상 정보에서 url이 없는 경우에 대해 예외처리를 했다. 이때는 대신 signatureCipher값이 존재하는데, 매우 오래전에 업로드된 동영상에서 이런 현상을 관찰할 수 있다.
다시 한 번 해당 부분의 코드를 보자.
for data in formats:
if 'url' not in data:
if 'signatureCipher' in data:
cipher_url = parse_qs(data['signatureCipher'])
data['url'] = cipher_url['url'][0]
data['s'] = cipher_url['s'][0]
data['is_otf'] = data.get('type') == 'FORMAT_STREAM_TYPE_OTF'
그런데, 아무리 봐도 암호를 해석하는 걸로는 보이지 않는다. parse_qs()는 쿼리스트링을 딕셔너리로 바꿔 주는 함수이다.
사실 Pytube에서 Cipher를 해독하는 함수는 따로 있다. cipher.py가 바로 그것이다. __main__.py에서 이를 찾아냈다.
line 175
try:
extract.apply_signature(stream_manifest, self.vid_info, self.js)
except exceptions.ExtractError:
# To force an update to the js file, we clear the cache and retry
self._js = None
self._js_url = None
pytube.__js__ = None
pytube.__js_url__ = None
extract.apply_signature(stream_manifest, self.vid_info, self.js)
apply_signature()에 들어가 보면
'''
Apply the decrypted signature to the stream manifest.
:param dict stream_manifest:
Details of the media streams available.
:param str js:
The contents of the base.js asset file.
'''
cipher = Cipher(js=js)
js파일을 함께 넘겨주며 해독 작업을 수행한다. 설명이 친절하다.
cipher.py의 내용이 어떻게 되어 있는지는 다음에 시간이 나면 알아보기로 하고, js파일이 어디서 왔는지 간단히 살펴보자.
결론만 말하자면, https://www.youtube.com/embed/{video_id} 주소에 get 요청을 보내 html을 받아오고, 이를 파싱해 base.js의 주소를 알아낸 다음, 한 번 더 get 요청을 보내 js파일을 받아온다. 상당히 비효율적인 루틴인데, 더 좋은 방법이 있는지도 다음에 알아보기로 하자. 아래는 관련 코드이다.
@property
def js(self):
if self._js:
return self._js
# If the js_url doesn't match the cached url, fetch the new js and update
# the cache; otherwise, load the cache.
if pytube.__js_url__ != self.js_url:
self._js = request.get(self.js_url)
pytube.__js__ = self._js
pytube.__js_url__ = self.js_url
else:
self._js = pytube.__js__
return self._js
@property
def js_url(self):
if self._js_url:
return self._js_url
if self.age_restricted:
self._js_url = extract.js_url(self.embed_html)
else:
self._js_url = extract.js_url(self.watch_html)
return self._js_url
@property
def embed_html(self):
if self._embed_html:
return self._embed_html
self._embed_html = request.get(url=self.embed_url)
return self._embed_html
# video_id part of /watch?v=<video_id>
self.video_id = extract.video_id(url)
self.watch_url = f"https://youtube.com/watch?v={self.video_id}"
self.embed_url = f"https://www.youtube.com/embed/{self.video_id}"
재미있게도, InnerTube API를 통해 휙득한 자료에선 아직까지 url 대신 signatureCipher 값이 있는 경우를 발견하지 못했다. 좋은 거겠지…?
결론
이번 분석의 의의는 새로운 방식의 youtube API 발견 으로 간단히 요약된다. 이를 이용해 제한 없는 api를 이용할 수 있으며, 일반적인 html 파싱에 비해 훨씬 간단하기도 하다.
InnterTube API를 이용해 cli 동영상 검색 기능 및 다운로드 프로그램을 만들 수 있겠다. 또는 Chrome 확장 프로그램으로 개발하는 것도 좋아 보인다. 흠.
오늘은 여기까지.
그럼 다음에,
Gabriel-Dropout
at 14:40
